分布式ID生成算法

Contents
在实际业务建模过程中,大多数情况下我们需要通过一个唯一ID来标记一条数据例如用户信息等,而这些唯一ID需要在插入数据库之前在程序中生成,如果存在多个不同的后端pod同时接受请求,则需要使用一个分布式的ID生成器来解耦ID生成与后端Pod的依赖。
因此一个分布式的ID生成器需要满足以下几个要求:
- 唯一性:不同client任意时刻生成的id需要不同;
- 高性能:ID生成往往涉及到新用户和新业务的接入,所以需要高性能的ID生成器,ID生成器不应该成为业务的瓶颈
- 高可用:ID生成器的不可用往往会导致业务的不可用;
常见的ID生成算法包括:
- UUID
- 数据库自增ID
- 号段模式
- 雪花算法
UUID
在go中,可以简单通过
|
|
然后在代码中生成uuid
|
|
即可生成一个长度为36的uuid
优点:
- 简单,成本低,占用资源低,基本不可能重复
缺点:
- 无序:随机字符串,不具备自增的趋势,如果以uuid为主键,则主键索引分页的概率较大,数据页越多,磁盘IO的次数也会越多,查询速度也会越慢;自增主键记录会顺序添加到当前索引节点的后续位置,当16kb的一页写满时,会自动新建一页。而非自增主键的插入顺序类似于随机,插入容易导致B+树数据的频繁的移动和分页操作;
- 长度过长在MySQL :: MySQL 5.7 Reference Manual :: 14.6.2.1 Clustered and Secondary Indexes中提到
If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.;
数据库自增ID
通过在数据库中新建一个表,使用数据库的自增ID作为业务的ID
|
|
优点:
- 实现简单,ID单调自增,数值类型查询速度快;
缺点:
- DB可能存在宕机风险;
- MySQL查询QPS有限制;
其他优化可以通过扩展DB的实例数量,设定ID的起始值和步长来解决MySQL的瓶颈,但是这种类型的ID扩展性不强,扩容的时候操作风险高。
设定起始值的时候有个坑,如果设定的起始值1,但是没有往表里插入数据,这个时候数据库宕机重启了,此时起始值会失效!
号段模式
在数据库自增ID中,使用的时数据库提供的自增ID的多业务可扩展性不强,可以通过号段模式来优化
号段模式为:业务每次使用事务的方式来数据库取一个号段存储到内存中,然后每次生成ID的时候从内存中取数据;
|
|
通过biz_type来区分不同的业务,每次业务取号时,新建一个事务,然后锁定对于的biz_type的行,更新max_id,写表,提交事务,然后就可以获取到一个完整的ID;
优点:
- 便于扩展;
- ID为64位且有递增趋势;
- 服务内有缓存,DB暂时性宕机对业务基本无影响;
max_id可以自定义,便于迁移;
缺点:
- ID不随机;
- 号段用完的时候需要取号段,此时会对业务产生一定的影响,如果取号段的时候DB挂掉,则业务不可用;
- DB宕机时间过长会导致整个系统不可用;
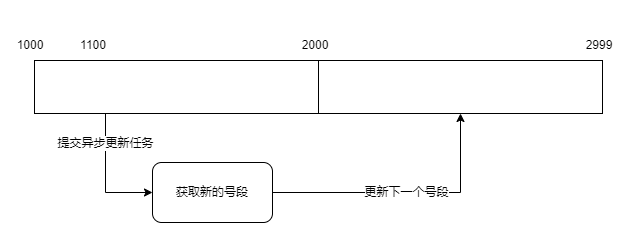
为了解决上述问题,可以通过采用下面的架构:内存中存储了多个号段,当号段消耗超过一定比例的时候,启动一个异步任务取更新号段,此时即使DB宕机,服务也会缓存一定的号段(可以为峰值QPS的倍数)维持业务的运行;
雪花算法
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法。Snowflake生成的是Long类型的ID

SnowflakeID组成结构如上图:正数位(1 bit)+时间戳(41 bits)+机器ID(10 bits)+ 自增值(12 bits)
从上面的介绍可以看出
- 同一ms时间内,每个节点最大可生成的ID数量为4096个;
- 最多支持1024个实例;
- 41bits的时间戳会在69年内耗尽(所以不要使用当前时间戳,使用相对值);
其他各种类型的ID生成器都是号段模式和雪花算法的变种:
- 美团leaf-snowflake:通过zk管理节点的worker-id并在本地缓存worker-id来解决zk的强依赖问题;通过周期性的上传机器时间来解决时间回拨问题;
- 百度uid-generatorbaidu/uid-generator: UniqueID generator (github.com):通过与数据库配合自定义时间戳、worker-id和序列号
- didi/tinyid: ID Generator id生成器 分布式id生成系统,简单易用、高性能、高可用的id生成系统 (github.com)
Author hlday
LastMod 2022-03-13