Raft

Contents
Raft选举过程
角色
每个节点存在三种不同的角色:
- Follower
- Candidate
- Leader
并且每个节点同一时刻只能是其中一种角色。
|
|
Follower
节点处于Follower状态时,会首先初始化一个随机过期时间
|
|
如果超过该时间没有和leader成功通信,则该节点会认为leader丢失,并尝试进入Candidate状态。
|
|
Follower节点会处理一些RPC请求
|
|
其中包括RequestVoteRequest,即请求成为leader的选举请求,如果节点发现
- 存在leader且leader!=请求的节点且不处于leader切换阶段:拒绝选举请求
req.Term < r.getCurrentTerm():拒绝选举请求req.Term > r.getCurrentTerm(): 进入Follower状态并将当前的Term设置为req.TermlastTerm > req.LastLogTerm: 拒绝选举请求lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex:拒绝选举请求 从以上5中情况可以看到,选举并不仅仅是根据时间来确定的(先到先得),而是根据时间,存储情况来决定节点是否投票给对应的Candidate,如果集群中一个节点的存储落后于集群中其他节点,即使该节点先发起Leader选举请求,也会被集群中其他节点拒绝。
Candidate
如果节点超时没有收到leader的心跳,则会进入Candidate状态。Candidate状态开始的时候,节点会首先给自己投一票并且初始化一个随机超时时间,随后会计算需要的投票的节点数
|
|
votesNeeded的计算方式为配置中的最后的所有的节点数/2+1,如果集群中只存在两个活着的节点,则需要的最小投票数量为2
|
|
如果candidate收到rpc的回复,则会:
vote.Term > r.getCurrentTerm():进入follower状态vote.Granted==true:grantedVotes++,如果grantedVotes >= votesNeeded,则进入leader状态
所以Candidate是一种中间状态,每次选举会存在三种结果
- 超时重新进行选举;
- 发现req.Term大于自己的term则进入Follower状态;
- 获取足够多的投票进入Leader状态;
Leader
Leader的运行逻辑比较简单,首先初始化一些leader的配置,然后运行一个死循环r.leaderLoop()
|
|
Leader需要处理各种RPC请求,写入数据,并检测集群的状态等。Leader可能会退化为Follower:
- 如果在LeaderLeaseTimeout时间段内,Leader并未与集群中大多数节点成功通信,则Leader会退化为Follower;
- 如果Leader接收到比当前term更大的term,则会退化为Follower
所以上述三种状态可以用下图表示
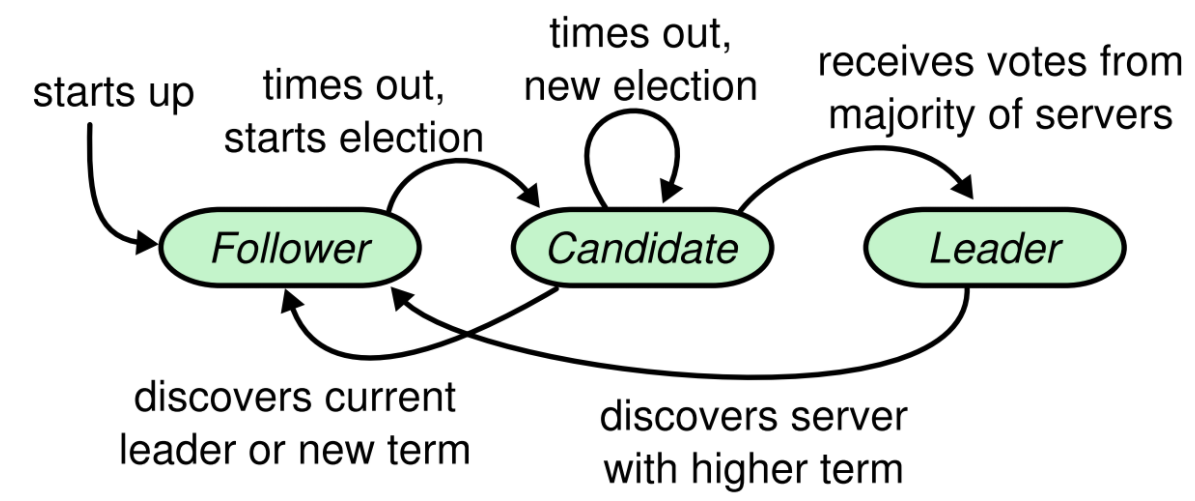
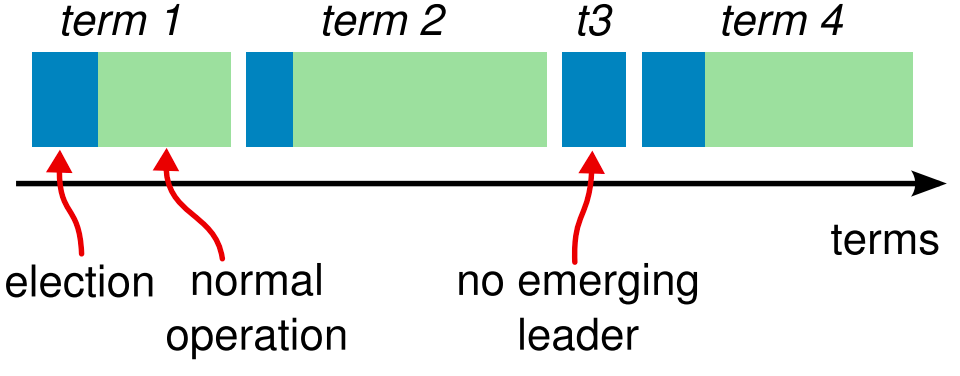
同时term可以用下图来表示
选举过程
-
节点在加入集群后处于follower状态;
-
如果follower节点在超时时间(election timeout)后没有收到leader的心跳,会进入candidate状态(开启一个新的election term),candidate状态下会发起选举投票:
- candidate会首先给自己投票
- 然后给所有节点发送一个投票消息
- 如果收到半数以上节点的同意请求则进入leader状态、然后发送
Append Entries(会按照heartbeat timeout周期性的发送消息)消息给所有节点

The election timeout is the amount of time a follower waits until becoming a candidate. The election timeout is randomized to be between 150ms and 300ms.
通过随机的选举超时可以有效避免脑裂问题:5节点,宕机一个节点,如果两个candidate同时发起请求,而只收到两票,就都不会赢得选举,然后随机等待一个election timeout,然后再次发起请求,先发起请求的节点成为leader的概率要远大于后发起请求的节点;
-
其他节点收到投票后会有两种选择:
- 如果在election term没有投过票则同意选举请求、重置election timeout并进入follower状态
- 拒绝选举请求
Log replication
日志格式
log的数据结构如下
|
|
log由index,term,type和data组成
日志处理流程
-
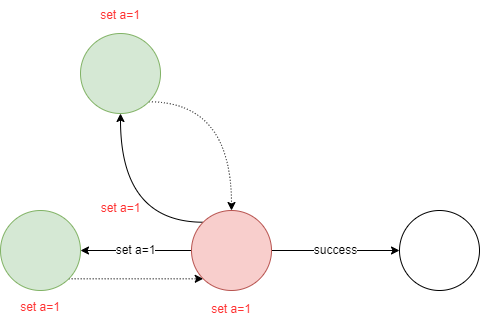
所有的请求都需要有Leader处理,并且都会被追加到Leader的log中,如下图所示,client发送了
set a=1的请求,leader接收到请求后将数据存储到log中,但是此时并没有commit,所以leader不会更新当前a的值。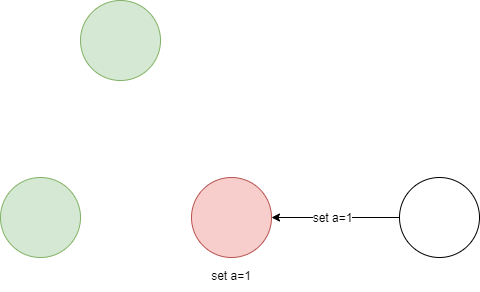
-
为了完成commit,Leader首先向所有的Follower发送replicate请求,然后等待集群中大多数节点返回确认信息
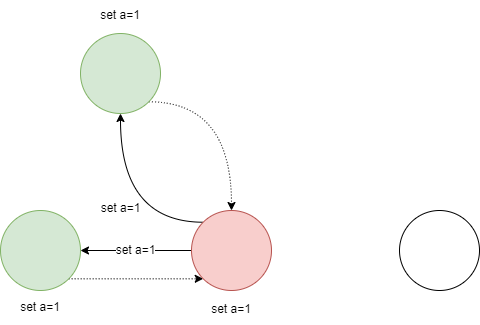
-
大多数节点返回了确认信息后,Leader可以commit并将a设置为1,然后Leader发送请求给Follower说明a=1已经commit,Follower接收到请求后将执行commit操作,此时整个系统就a的值处于一致性状态
一些问题
通过k8s部署的3节点consul先后挂掉两个节点后无法正常工作
-
初始状态下,consul集群工作正常

-
刚开始如果1挂掉,此时consul依然能够正常工作,因为活着的两个节点知道彼此的存在,此时0和2上的last_configuration变成了0和2,去掉了挂掉的1节点,但是注意,此时1节点上存储的last_configuration还是0、1、2;

-
如果此时1节点起来,然后在1节点加入集群之前,2节点挂掉,此时整个集群的信息如下,因为1还没有加入集群,所以0节点的last_configuration还是存储的0、2;所以如果0要发起投票,只能给2发(但是此时2已经挂掉了),所以0不能依靠投票成为leader;1节点存储了正确的节点信息0、1、2,所以0节点能够正常发起投票,但是1的last_index小于0的last_index,所以1给0发起的投票会被0拒绝,因此1节点也无法通过投票成为leader;此时整个consul集群处于无法工作的状态;

看raft的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119func (r *Raft) requestVote(rpc RPC, req *RequestVoteRequest) { defer metrics.MeasureSince([]string{"raft", "rpc", "requestVote"}, time.Now()) r.observe(*req) // Setup a response resp := &RequestVoteResponse{ RPCHeader: r.getRPCHeader(), Term: r.getCurrentTerm(), Granted: false, } var rpcErr error defer func() { rpc.Respond(resp, rpcErr) }() // Version 0 servers will panic unless the peers is present. It's only // used on them to produce a warning message. if r.protocolVersion < 2 { resp.Peers = encodePeers(r.configurations.latest, r.trans) } // Check if we have an existing leader [who's not the candidate] and also // check the LeadershipTransfer flag is set. Usually votes are rejected if // there is a known leader. But if the leader initiated a leadership transfer, // vote! var candidate ServerAddress var candidateBytes []byte if len(req.RPCHeader.Addr) > 0 { candidate = r.trans.DecodePeer(req.RPCHeader.Addr) candidateBytes = req.RPCHeader.Addr } else { candidate = r.trans.DecodePeer(req.Candidate) candidateBytes = req.Candidate } // For older raft version ID is not part of the packed message // We assume that the peer is part of the configuration and skip this check if len(req.ID) > 0 { candidateID := ServerID(req.ID) // if the Servers list is empty that mean the cluster is very likely trying to bootstrap, // Grant the vote if len(r.configurations.latest.Servers) > 0 && !hasVote(r.configurations.latest, candidateID) { r.logger.Warn("rejecting vote request since node is not a voter", "from", candidate) return } } if leaderAddr, leaderID := r.LeaderWithID(); leaderAddr != "" && leaderAddr != candidate && !req.LeadershipTransfer { r.logger.Warn("rejecting vote request since we have a leader", "from", candidate, "leader", leaderAddr, "leader-id", string(leaderID)) return } // Ignore an older term if req.Term < r.getCurrentTerm() { return } // Increase the term if we see a newer one if req.Term > r.getCurrentTerm() { // Ensure transition to follower r.logger.Debug("lost leadership because received a requestVote with a newer term") r.setState(Follower) r.setCurrentTerm(req.Term) resp.Term = req.Term } // Check if we have voted yet lastVoteTerm, err := r.stable.GetUint64(keyLastVoteTerm) if err != nil && err.Error() != "not found" { r.logger.Error("failed to get last vote term", "error", err) return } lastVoteCandBytes, err := r.stable.Get(keyLastVoteCand) if err != nil && err.Error() != "not found" { r.logger.Error("failed to get last vote candidate", "error", err) return } // Check if we've voted in this election before if lastVoteTerm == req.Term && lastVoteCandBytes != nil { r.logger.Info("duplicate requestVote for same term", "term", req.Term) if bytes.Compare(lastVoteCandBytes, candidateBytes) == 0 { r.logger.Warn("duplicate requestVote from", "candidate", candidate) resp.Granted = true } return } // Reject if their term is older lastIdx, lastTerm := r.getLastEntry() if lastTerm > req.LastLogTerm { r.logger.Warn("rejecting vote request since our last term is greater", "candidate", candidate, "last-term", lastTerm, "last-candidate-term", req.LastLogTerm) return } if lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex { r.logger.Warn("rejecting vote request since our last index is greater", "candidate", candidate, "last-index", lastIdx, "last-candidate-index", req.LastLogIndex) return } // Persist a vote for safety if err := r.persistVote(req.Term, candidateBytes); err != nil { r.logger.Error("failed to persist vote", "error", err) return } resp.Granted = true r.setLastContact() return }如果
if lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex,则会拒绝投票请求;但是lastIndex是通过appendEntries来更新的,appendEntries只能由leader发起。
k8s部署的consul有如下几个坑:
- 通过statefulset部署的consul集群,在一个宿主机挂掉时间过长的情况下,可能会发送pod漂移,consul pod会迁移到其他节点上去,此时如果使用的存储不是分布式存储而是localpv,会发生丢数据的问题(可以不在server上存储数据来解决这个问题,也可以使用kubemod/kubemod: Universal Kubernetes mutating operator (github.com));
- 需要指定node-id,要不然会出现pod重启到其他节点,node-id和pod-ip均发生变化而导致很多奇怪的问题;
- 部署在k8s中,由于pod-ip不确定,则consul会强依赖k8s的域名解析;
- 有些分布式存储会在网络或节点压力大的情况下变为
read only,注意,这个会导致consul集群直接不工作!挂在的pv变为read only时需要手动删除pod重建pod。
有用的链接
Author hlday
LastMod 2022-03-08