Go中的错误的懒汉式双重检测单例编程模式带来的思考

Contents
如果要初始化一个etcd连接,使用如下代码:
|
|
这个代码在熟悉Java的同学看来是没有问题的,但是在Go代码中,两个协程并发调用时,可能会产生意想不到的问题【data race】。要理解这个问题得,先需要了解Go的内存模型和CPU缓存一致性协议。
Go内存模型
内存模型:In computing, a memory model describes the interactions of threads through memory and their shared use of the data. 内存模型描述了多线程如何通过内存的交互来共享数据。
Go的内存模型定义了一个协程能够读取到其他协程对变量的修改的条件。
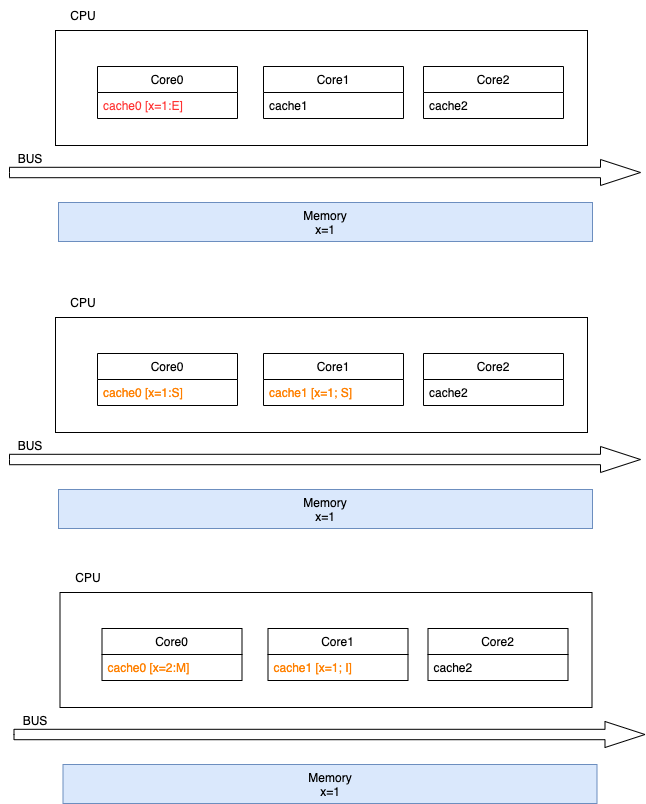
多核CPU多级缓存一致性协议MESI
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱。这里就引出了一个一致性的协议MESI。
MESI协议缓存状态
MESI 是指4中状态的首字母。每个Cache line有4个状态,可用2个bit表示,它们分别是:
- 已修改Modified (M):缓存行是脏的(dirty),与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S).
- M->S
- 独占Exclusive (E):缓存行只在当前缓存中,但是干净的(clean)–缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
- E->S
- E->M
- 共享Shared (S):缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃。
- 无效Invalid (I):缓存行是无效的
对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
MESI优化和他们引入的问题
缓存的一致性消息传递是要时间的,这就使其切换时会产生延迟。当一个缓存被切换状态时其他缓存收到消息完成各自的切换并且发出回应消息这么一长串的时间中CPU都会等待所有缓存响应完成。可能出现的阻塞都会导致各种各样的性能问题和稳定性问题。
CPU切换状态阻塞解决-存储缓存(Store Bufferes)
比如你需要修改本地缓存中的一条信息,那么你必须将I(无效)状态通知到其他拥有该缓存数据的CPU缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。应为这个等待远远比一个指令的执行时间长的多。
Store Bufferes
为了避免这种CPU运算能力的浪费,Store Bufferes被引入使用。处理器把它想要写入到主存的值写到缓存,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。
这么做有两个风险
Store Bufferes的风险
-
就是处理器会尝试从存储缓存(Store buffer)中读取值,但它还没有进行提交。这个的解决方案称为Store Forwarding,它使得加载的时候,如果存储缓存中存在,则进行返回。
-
保存什么时候会完成,这个并没有任何保证。
|
|
试想一下开始执行时,CPU A保存着finished在E(独享)状态,而value并没有保存在它的缓存中。(例如,Invalid)。在这种情况下,value会比finished更迟地抛弃存储缓存。完全有可能CPU B读取finished的值为true,而value的值不等于10。
即isFinsh的赋值在value赋值之前。
这种在可识别的行为中发生的变化称为重排序(reordings)。注意,这不意味着你的指令的位置被恶意(或者好意)地更改。
它只是意味着其他的CPU会读到跟程序中写入的顺序不一样的结果。
硬件内存模型
执行失效也不是一个简单的操作,它需要处理器去处理。另外,存储缓存(Store Buffers)并不是无穷大的,所以处理器有时需要等待失效确认的返回。这两个操作都会使得性能大幅降低。为了应付这种情况,引入了失效队列。它们的约定如下:
- 对于所有的收到的Invalidate请求,Invalidate Acknowlege消息必须立刻发送
- Invalidate并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。
- 处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate。
即便是这样处理器已然不知道什么时候优化是允许的,而什么时候并不允许。
干脆处理器将这个任务丢给了写代码的人。这就是内存屏障(Memory Barriers)。
写屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一条告诉处理器在执行这之后的指令之前,应用所有已经在存储缓存(store buffer)中的保存的指令。
读屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一条告诉处理器在执行任何的加载前,先应用所有已经在失效队列中的失效操作的指令。
在没有手动设置同步的情况下,处理器无法保证读写顺序。在Go中,这个行为有个定义为Happen Before
Happen Before
To specify the requirements of reads and writes, we define happens before, a partial order on the execution of memory operations in a Go program. If event e1 happens before event e2, then we say that e2 happens after e1. Also, if e1 does not happen before e2 and does not happen after e2, then we say that e1 and e2 happen concurrently.
为了满足读写顺序,需要定义happen before,如果e1发生的时间早于e2之前,可以认为e1happen beforee2,如果e2早于e1,则e2happen beforee1,如果不满足上述两种情况,则e1和e2是并发的。
如果读r能够感知写w对v修改,则需要满足两个条件:
- r不
happen beforew - r和w之间没有其他w
为了保证读r能够感知到写w对v的修改,确保w是唯一能够被感知到写v的写,也就是说,r能够保证感知到w,需要满足两个条件:
- w
happen beforer; - w和r之间没有其他对共享变量v的修改;
单协程不存在竞争的问题,但是多协程时,则需要同步机制建立happens-before机制。
Go中有几种确保Happen Before
- init:先导入的包happend before后导入的包;
- goroutine:创建协程happen before协程所有的其他操作,销毁协程happen after其他所有操作;
- channel:同一个数据的发送总happen before同一个数据的消费;
- Lock:用锁来保证happen before
问题
了解了上述基础知识后,再看代码:
|
|
上述代码,对config的修改在临界区内,其他协程对修改是可见的,但是为什么还是会在client==nil会发生data race呢。
主要原因是对config进行初始化的操作并不是原子操作
|
|
上述赋值操作会分为几个步骤:
- new一个clientv3.Config
- 设置Endpoints&DialTimeout
- 把new的对象赋值给config
如果这个时候,编译器发生了重排序,可能会变成:
- new一个clientv3.Config
- 把new的对象赋值给config
- 设置Endpoints&DialTimeout
如果拿到锁的协程在第二步的时候,另一个协程判断config==nil的时候,就会为false,直接将config返回了,此时可能会发生一些意想不到的问题。可以直接用sync.once解决上述问题。
参考
Author hlday
LastMod 2022-07-29